

Die Verwendung mehrerer verborgener Schichten im maschinellen Lernen (auch „Deep Learning“ genannt) hat die Leistung herkömmlicher Techniken zur Lösung verschiedener Probleme übertroffen, insbesondere im Bereich der Mustererkennung und Objekterkennung. Eine der beliebtesten Architekturen im Deep Learning ist das Convolutional Neural Network (CNN), das häufig für Klassifizierungsaufgaben verwendet wird.
CNNs haben im Bereich der Computervision eine entscheidende Rolle gespielt, bei der es darum geht, Maschinen das Verstehen visueller Daten beizubringen. 2012 entwickelte ein Forscherteam der Universität Toronto ein KI-Modell namens AlexNet, benannt nach seinem Hauptentwickler Alex Krizhevsky. Dieses Modell konnte eine beispiellose Genauigkeit von 85 % bei der Bilderkennung erreichen und übertraf damit die Genauigkeit des Zweitplatzierten im ImageNet-Computervision-Wettbewerb mit 74 % bei weitem.
Der Erfolg von AlexNet beruhte größtenteils auf der Verwendung von CNNs, einer Art neuronalem Netzwerk, das die Funktionsweise des menschlichen Sehens nachahmt. Im Laufe der Jahre sind CNNs zu einem wesentlichen Bestandteil vieler Computer-Vision-Anwendungen geworden und sind heute ein häufiges Thema in Online-Computer-Vision-Kursen. Daher ist es für jeden, der sich für dieses Gebiet interessiert, wichtig, die Funktionsweise von CNNs und den CNN-Algorithmus im Deep Learning zu verstehen.
In diesem Beitrag besprechen wir:
- Was Convolutional Neural Networks sind
- So funktionieren Convolutional Neural Networks
- Gängige Convolutional-Neural-Network-Architekturen
Lass uns anfangen!
Was ist ein Convolutional Neural Network?
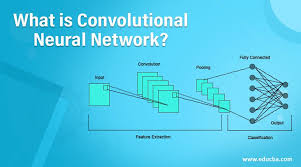
Ein Convolutional Neural Network (CNN) ist eine Deep-Learning-Architektur, die ein Bild aufnimmt, Faltungen und Pooling anwendet und dann eine vollständig verbundene Schicht und Aktivierungsfunktion durchläuft, um eine Ausgabe zurückzugeben. Diese Ausgabe enthält normalerweise eine Klassifizierung des Bildinhalts oder Informationen über die Position verschiedener Objekte in einem Bild.
Im Gegensatz zu herkömmlichen neuronalen Netzwerken, die hauptsächlich auf Matrixmultiplikationen basieren, verwenden CNNs eine Technik namens Faltung. Mathematisch gesehen ist Faltung eine Operation, bei der zwei Funktionen kombiniert werden, um eine dritte Funktion zu erstellen, die darstellt, wie eine Funktion die Form der anderen ändert. Es finden weitere Verarbeitungsphasen statt, darunter Pooling und Durchlaufen vollständig verbundener Schichten sowie eine Aktivierungsfunktion zum Zurückgeben einer Vorhersage. Unten sehen Sie eine typische Architektur eines CNN.
Die Faltungsschichten innerhalb eines CNN scannen durch den Faltungsprozess das Bild effektiv und extrahieren wichtige Merkmale wie Kanten, Texturen und Formen. Diese Merkmale werden dann durch mehrere Schichten geleitet und mithilfe von Techniken wie Pooling und Aktivierungsfunktionen verarbeitet, was zu einer kompakten, aber dennoch informativen Darstellung des Originalbilds führt. Diese kompakte Darstellung wird dann als Eingabe für die vollständig verbundenen Schichten des Netzwerks verwendet, die die endgültigen Vorhersagen treffen.
Obwohl es hilfreich sein kann, die mathematischen Details hinter der Faltung zu verstehen, ist es nicht unbedingt erforderlich, um das Gesamtkonzept eines CNN zu verstehen.
Auf einer hohen Ebene ist ein CNN darauf ausgelegt, ein Bild aufzunehmen und es in eine Darstellung umzuwandeln, die ein neuronales Netzwerk verstehen kann, wobei gleichzeitig wichtige Merkmale erhalten bleiben, die genaue Vorhersagen ermöglichen.
CNNs vs. Feedforward-Neuralnetze
Um CNNs im Kontext richtig zu verstehen, ist es wichtig, ihren Vorgänger zu berücksichtigen: Feedforward-Neuralnetze.
Ein Feedforward-Neuralnetz ist ein neuronales Netz, das Daten in einem einzigen Durchgang verarbeitet, wobei die Eingabe mehrere Schichten durchläuft, bevor sie die Ausgabe erreicht. Bei der Bildverarbeitung haben Feedforward-Netze eine große Einschränkung: das Risiko einer Überanpassung.
Ein Bild kann als Zahlenmatrix mit der Form (Zeilen * Spalten * Anzahl der Kanäle) dargestellt werden. Ein typisches reales Bild wäre mindestens 200 * 200 * 3 Pixel groß. Ein Ansatz zum Einspeisen eines Bilds in ein Feedforward-Neuralnetzwerk wäre, das Bild in eine 1D-Matrix zu glätten. Dies würde jedoch eine große Anzahl von Neuronen und eine entsprechende Anzahl von Gewichten in der ersten verborgenen Schicht erfordern. Dies führt zu einer großen Anzahl von Parametern, was das Risiko einer Überanpassung erhöhen kann.
Im Gegensatz dazu gehen Convolutional Neural Networks die Bildverarbeitung auf eine andere Weise an. Anstatt das Bild zu glätten und in einem Durchgang zu verarbeiten, verarbeiten CNNs jeweils kleine Ausschnitte eines Bildes und bewegen sich über das gesamte Bild. Dadurch kann das Netzwerk wesentliche Merkmale des Bildes erlernen und dabei weniger Neuronen und Parameter verwenden. Dieser Ansatz macht CNNs effizienter und weniger anfällig für Überanpassung als Feedforward-Neural Networks.
Wie funktionieren Convolutional Neural Networks?
Bevor wir uns mit der Funktionsweise von Convolutional Neural Networks befassen, ist es wichtig, die Grundlagen von Bildern und ihrer Darstellung zu verstehen.
Ein Bild kann als Matrix von Pixelwerten dargestellt werden, wobei jedes Pixel einen bestimmten Farbwert hat. RGB-Bilder, der am häufigsten verwendete Bildtyp, haben drei Ebenen, die die Farbkanäle Rot, Grün und Blau darstellen. Graustufenbilder hingegen haben nur eine Ebene. Diese Ebene stellt die Intensität des Pixels dar.
Die Anzahl der Pixel in einem Bild bestimmt dessen Auflösung. Ein Bild mit höherer Auflösung verfügt über mehr Pixel und somit über detailliertere Informationen.
Nachdem wir nun den Hintergrund besprochen haben, müssen wir uns mit der Funktionsweise von CNNs befassen. Sehen wir uns ein Beispiel mit Graustufenbildern an, da deren Struktur nicht so komplex ist wie die von RGB-Bildern.
Was ist eine Faltung?
Eine Faltung ist ein Prozess, bei dem eine kleine Matrix, Filter oder Kernel genannt, auf ein Eingabebild angewendet wird, um wichtige Merkmale zu extrahieren. Der Filter wird über das Bild bewegt, wobei die Werte an jeder Position mit den entsprechenden Werten im Bild multipliziert und die Ergebnisse summiert werden.
Dieser Prozess führt zu einem „gefalteten Merkmal“, das dann zur weiteren Verarbeitung an die nächste Ebene weitergegeben wird. Hier sehen Sie eine Animation des Prozesses, der auf ein 5×5-Raster von Pixeldaten angewendet wird:
Faltungsneuronale Netzwerke bestehen aus einer Reihe miteinander verbundener Schichten künstlicher „Neuronen“. Diese künstlichen Neuronen sind mathematische Funktionen, die mehrere Eingaben verarbeiten, gewichten und einen Aktivierungswert zurückgeben.
Die erste Schicht des ConvNet ist für die Erkennung grundlegender Merkmale wie Kanten, Ecken und anderer einfacher Formen verantwortlich. Während das Bild durch aufeinanderfolgende Schichten geleitet wird, kann das Netzwerk komplexere Merkmale wie Objekte und Gesichter erkennen, indem es auf den in den vorherigen Schichten gesammelten Informationen aufbaut. Während das Bild tiefer im Netzwerk verarbeitet wird, kann es noch komplexere Merkmale wie Objekte, Gesichter usw. erkennen.
Die letzte Faltungsschicht eines Convolutional Neural Network generiert eine „Aktivierungskarte“. Bei Klassifizierungsaufgaben beispielsweise verwendet eine Klassifizierungsschicht diese Karte, um die Wahrscheinlichkeit zu bestimmen, dass das Eingabebild zu einer bestimmten „Klasse“ gehört.
Diese Wahrscheinlichkeit wird als eine Reihe von Vertrauenswerten mit Werten zwischen 0 und 1 dargestellt. Wenn das ConvNet beispielsweise darauf ausgelegt ist, Katzen, Hunde und Pferde zu erkennen, ist die Ausgabe der letzten Ebene die Wahrscheinlichkeit, dass das Eingabebild eines dieser Tiere enthält. Je höher der Wert, desto wahrscheinlicher ist es, dass das Bild die entsprechende Klasse enthält.
CNNs in der Objekterkennung
CNNs können zur Objekterkennung verwendet werden, einer Aufgabe, bei der es darum geht, Objekte in einem Bild oder Video zu lokalisieren und zu identifizieren. Die Ausgabe eines CNN wäre in diesem Fall eine Reihe von Begrenzungsrahmen um die Objekte im Bild, zusammen mit Klassenbezeichnungen und Konfidenzwerten, die angeben, um welches Objekt es sich handelt und wie sicher sich das Netzwerk bei seinen Vorhersagen ist.
Es gibt verschiedene Ansätze für die Verwendung von CNNs zur Objekterkennung, aber ein gängiger Ansatz ist die Verwendung eines zweistufigen Frameworks, wie beispielsweise der beliebten Modellfamilie R-CNN (Regions with Convolutional Neural Networks). In der ersten Phase wird das Netzwerk verwendet, um Kandidatenobjektbereiche im Bild vorzuschlagen, sogenannte „Regionsvorschläge“.
Diese Regionsvorschläge werden dann in einer zweiten Phase verarbeitet, in der ein vollständig verbundenes Netzwerk verwendet wird, um die Objekte in den Regionen zu klassifizieren und die Begrenzungsrahmen zu verfeinern. Neuere Ansätze wie YOLO (You Only Look Once) und RetinaNet verwenden einen einstufigen Ansatz, bei dem das Netzwerk die Begrenzungsrahmen, Klassenbezeichnungen und Vertrauenswerte in einem einzigen Durchgang direkt aus dem Eingabebild vorhersagt. Diese Modelle sind tendenziell schneller als die zweistufigen Ansätze, weisen jedoch häufig eine etwas geringere Genauigkeit auf.
Unabhängig von der spezifischen Architektur besteht die Hauptidee hinter der Verwendung von CNNs zur Objekterkennung darin, die Faltungsschichten zu nutzen, um aussagekräftige, unterscheidungskräftige Merkmale aus dem Bild zu extrahieren und diese Merkmale dann zu verwenden, um Vorhersagen über die Objekte im Bild zu treffen.
Schichten in Convolutional Neural Networks
In diesem Abschnitt geben wir einen umfassenden Überblick über die Schichten, die üblicherweise beim Aufbau von Convolutional-Neural-Network-Architekturen verwendet werden. Wir untersuchen die verschiedenen Schichtentypen, aus denen CNNs bestehen: die Pooling-Schicht, die Aktivierungsschicht, die Batch-Normalisierungsschicht, die Dropout-Schicht und die Klassifizierungsschicht. Fangen wir an!
Pooling-Schicht
Die Pooling-Schicht reduziert, ähnlich der zuvor besprochenen Convolutional-Schicht, die räumliche Größe der gefalteten Merkmale innerhalb eines Convolutional Neural Network.
Diese Reduzierung der räumlichen Größe wird durch Downsampling der gefalteten Merkmale erreicht. Dies dient dem doppelten Zweck, sowohl die zur Verarbeitung der Daten erforderliche Rechenleistung zu verringern als auch den Abstraktionsgrad der Merkmale zu erhöhen.
In CNNs werden zwei gängige Arten von Pooling-Techniken verwendet: Average Pooling und Max Pooling.
Max Pooling reduziert die räumliche Größe der gefalteten Features durch Downsampling. Dabei wird der Maximalwert eines Pixels aus einem vom Kernel abgedeckten Bildbereich ausgewählt.
Diese Technik verringert nicht nur die zur Verarbeitung der Daten erforderliche Rechenleistung, sondern dient auch zur Unterdrückung von Rauschen, indem sie verrauschte Aktivierungen verwirft und eine Rauschunterdrückung sowie eine Dimensionsreduzierung durchführt.
Andererseits gibt Average Pooling den Durchschnitt aller Werte aus dem vom Kernel abgedeckten Teil des Bildes zurück. Es dient zwar auch der Dimensionsreduzierung, verfügt jedoch nicht über die Rauschunterdrückungsfunktionen von Max Pooling.
Daher gilt Max Pooling in der Praxis allgemein als effektiver und robuster und bietet eine bessere Leistung als Average Pooling. Die Wahl zwischen diesen beiden Techniken hängt weitgehend von den spezifischen Anforderungen der Aufgabe und dem Rauschpegel im Datensatz ab.
Aktivierungsfunktionsebene
Die Aktivierungsfunktionsschicht hilft dem Netzwerk, nichtlineare Beziehungen zwischen Eingabe und Ausgabe zu lernen. Sie ist dafür verantwortlich, Nichtlinearität in das Netzwerk einzuführen und ihm die Modellierung komplexer Muster und Beziehungen in den Daten zu ermöglichen.
Die Aktivierungsfunktion wird normalerweise auf die Ausgabe jedes Neurons im Netzwerk angewendet. Sie nimmt die gewichtete Summe der Eingaben auf und erzeugt eine Ausgabe, die dann an die nächste Schicht weitergegeben wird.
Die am häufigsten verwendeten Aktivierungsfunktionen in CNNs sind:
- Gleichgerichtete Lineareinheit (ReLU)
- Sigmoid
- Tangens Hyperbolicus (tanh)
ReLU ist eine beliebte Wahl in CNNs, da es rechnerisch effizient ist und dazu neigt, spärliche Darstellungen der Eingabedaten zu erzeugen. Es gibt die Eingabe zurück, wenn sie positiv ist, und gibt 0 zurück, wenn sie negativ ist. Sigmoid und tanh sind andere nichtlineare Funktionen, werden aber in CNNs nicht so häufig verwendet wie ReLU, da sie bei großen Eingaben Gradienten nahe 0 erzeugen können. Die Aktivierungsfunktionsschicht kann als das „Gehirn“ des CNN betrachtet werden, wo die Eingabe in eine sinnvolle Darstellung der Daten umgewandelt wird. Sie ist eine grundlegende Komponente.
Weitere Informationen zu Aktivierungsfunktionen finden Sie in unserem umfassenden Leitfaden zu Aktivierungsfunktionen .
Batch-Normalisierungsebene
Die Batch-Normalisierungsschicht (BN) wird häufig in Convolutional Neural Networks verwendet, um die Eingabe jedes Neurons so zu normalisieren, dass sie einen Mittelwert von Null und eine Einheitsvarianz aufweist. Dies trägt dazu bei, den Lernprozess zu stabilisieren und das Problem der internen Kovariatenverschiebung zu verhindern, das auftritt, wenn sich die Verteilung der Eingaben an eine Schicht während des Trainingsprozesses ändert.
BN normalisiert die Ausgabe jedes Neurons unter Verwendung des Mittelwerts und der Standardabweichung des Eingabedatensatzes und wird normalerweise nach den Faltungs- und vollständig verbundenen Spielern angewendet.
Die Batch-Normalisierungsschicht hat mehrere positive Auswirkungen auf CNNs:
- BN kann den Trainingsprozess beschleunigen, indem es die interne Kovariatenverschiebung reduziert und höhere Lernraten ermöglicht.
- BN hilft dabei, das Modell zu regulieren, sodass es weniger anfällig für Überanpassung ist.
- Es hat sich gezeigt, dass BN die Generalisierungsleistung von CNNs verbessert, sodass diese bei unbekannten Daten eine bessere Leistung erzielen können.
- BN hilft, die Anzahl der Hyperparameter zu reduzieren, die angepasst werden müssen, wie z. B. die Lernrate. Dies führt zu einer Vereinfachung des Trainingsprozesses und einer Verbesserung der Generalisierung.
- BN ermöglicht es einem Modell, weniger empfindlich auf die Anfangswerte der Gewichte zu reagieren.
Zusammenfassend lässt sich sagen, dass die Batch-Normalisierung eine leistungsstarke Technik ist, die in CNNs häufig verwendet wird, um den Lernprozess zu stabilisieren und die Leistung des Modells zu verbessern. Sie normalisiert die Eingaben für jedes Neuron, reduziert die interne Kovariatenverschiebung und reguliert das Modell, was zu einer besseren Generalisierungsleistung führt.
Dropout-Ebene
Die Dropout-Schicht verwendet eine Regularisierungstechnik, um Überanpassung zu verhindern. Dies funktioniert, indem bei jeder Trainingsiteration ein Teil der Eingabeeinheiten zufällig auf Null gesetzt wird. Dadurch werden diese Einheiten effektiv „aussortiert“ und können nicht mehr zum Vorwärtsdurchlauf beitragen.
Dieser Prozess zwingt das Netzwerk, mehrere unabhängige Darstellungen der Eingabe zu lernen, wodurch es robuster gegenüber Änderungen der Eingabedaten wird und die Gefahr einer Überanpassung verringert wird. Dropout wird normalerweise auf die vollständig verbundenen Schichten eines CNN angewendet, kann aber auf jede Schicht angewendet werden.
Die Idee des Dropouts wurde von Hinton und seiner Bank inspiriert :
Angenommen, wir möchten ein Gesicht erkennen. Im Allgemeinen verfügen die Gesichter nicht immer über alle Gesichtsattribute wie Nase, Augen, Augen usw. Generell könnte etwas fehlen. Ich möchte mein Netzwerk beispielsweise auch für Gesichter mit verdecktem Auge trainieren. Daher ist es eine gute Idee, nicht alle Merkmale mitzuadaptieren, sondern eine Teilmenge dieser Merkmale zufällig zu lernen, um auf ungesehenen Daten besser verallgemeinern zu können und meinen Gesichtsdetektor zu zwingen, auch zu arbeiten, wenn nur einige der Attribute vorhanden sind.
Klassifizierungsebene
Die Klassifizierungsschicht ist die letzte Schicht in einem CNN. Diese Schicht erzeugt die Ausgabeklassenwerte für ein Eingabebild. In CNNs werden zwei Haupttypen von Klassifizierungsschichten verwendet: vollständig verbundene Schichten und globale Durchschnittspooling-Schichten.
Eine vollständig verbundene (FC) Schicht ist eine Standardschicht eines neuronalen Netzwerks, die alle Neuronen der vorherigen Schicht mit allen Neuronen der aktuellen Schicht verbindet. Die Ausgabe einer FC-Schicht wird berechnet, indem eine Gewichtsmatrix und ein Bias-Vektor auf die Eingabe angewendet werden, gefolgt von einer Aktivierungsfunktion. Die FC-Schicht wird dann mit einer Softmax-Aktivierung verbunden, um die Klassenwerte zu erzeugen.
Der Vorteil der Verwendung vollständig verbundener Schichten besteht darin, dass das Netzwerk dadurch komplexe Entscheidungsgrenzen zwischen Klassen erlernen kann. Andererseits können diese Schichten zu Überanpassung führen und erfordern eine große Anzahl von Parametern. Um diesen Problemen entgegenzuwirken, wurde Global Average Pooling (GAP) eingeführt.
Eine globale Durchschnitts-Pooling-Schicht ist eine Art Pooling-Schicht, die die räumlichen Dimensionen der Feature-Maps reduziert, indem sie den Durchschnittswert jeder Feature-Map nimmt. Die Ausgabe der GAP-Schicht ist ein 1D-Vektor mit einer Größe, die der Anzahl der Feature-Maps entspricht. Die GAP-Schicht ist mit einer vollständig verbundenen (FC) Schicht mit Softmax-Aktivierung verbunden, um die Klassenwerte zu erzeugen.
Der Vorteil der Verwendung von GAP-Schichten besteht darin, dass sie weniger anfällig für Überanpassung sind und weniger Parameter erfordern. Allerdings ermöglichen GAP-Schichten dem Netzwerk nicht, komplexe Entscheidungsgrenzen zwischen Klassen zu erlernen.
Zusammenfassend lässt sich sagen, dass vollständig verbundene Schichten für komplexe Entscheidungsgrenzen gut geeignet sind, aber viele Parameter erfordern und zu Überanpassung führen können. GAP-Schichten neigen weniger zu Überanpassung, sind aber weniger in der Lage, komplexe Entscheidungsgrenzen zu erlernen.
Bekannte CNN-Beispiele
Lassen Sie uns einige der gängigsten Implementierungen von Convolutional Neural Networks besprechen und dabei sowohl ältere als auch modernere CNNs berücksichtigen.
LeNet
LeNet wurde erstmals 1998 von Yann LeCun für die Erkennung handschriftlicher Ziffern vorgeschlagen. Es gilt als eines der ersten erfolgreichen CNNs und war die Grundlage für viele nachfolgende CNN-Architekturen.
Die Architektur von LeNet besteht aus mehreren Schichten, darunter:
- Zwei Faltungsschichten, jeweils gefolgt von einer Max-Pooling-Schicht, die zum Extrahieren von Merkmalen aus dem Eingabebild verwendet werden.
- Zur Klassifizierung der Merkmale werden zwei vollständig verbundene Schichten, auch dichte Schichten genannt, verwendet.
Die erste Faltungsschicht hat 6 Filter der Größe 5 x 5 und die zweite Faltungsschicht hat 16 Filter der Größe 5 x 5. Die Max-Pooling-Schicht reduziert die räumlichen Dimensionen der Feature-Maps, indem sie den Maximalwert in jedem Fenster der Größe 2 x 2 annimmt.
Die erste vollständig verbundene Schicht hat 120 Neuronen und die zweite vollständig verbundene Schicht hat 84 Neuronen. Die letzte Schicht ist eine vollständig verbundene Schicht mit 10 Neuronen, eines für jede Ziffernklasse.
LeNet ist eine relativ einfache Architektur, wird aber auch heute noch als Ausgangspunkt für viele Bildklassifizierungsaufgaben verwendet. Allerdings ist LeNet nicht so leistungsfähig wie viele neuere Architekturen.
AlexNet
AlexNet wurde 2012 von Alex Krizhevsky, Ilya Sutskever und Geoffrey Hinton vorgeschlagen. Es war das Gewinnermodell der ImageNet Large Scale Visual Recognition Challenge (ILSVRC) im Jahr 2012. AlexNet war das erste CNN, das bei diesem Benchmark die Leistung traditioneller, von Hand entworfener Modelle übertraf.
Die Architektur von AlexNet besteht aus mehreren Schichten, darunter:
- Fünf Faltungsschichten, jeweils gefolgt von einer Max-Pooling-Schicht, die zum Extrahieren von Merkmalen aus dem Eingabebild verwendet werden.
- Drei vollständig verbundene Schichten, auch dichte Schichten genannt, die zur Klassifizierung der Merkmale verwendet werden.
Die ersten beiden Faltungsschichten haben 96 Filter der Größe 11×11, die nächsten beiden Faltungsschichten haben 256 Filter der Größe 5×5 und die letzte Faltungsschicht hat 384 Filter der Größe 3×3. Die Max-Pooling-Schicht reduziert die räumlichen Dimensionen der Feature-Maps, indem sie den Maximalwert in jedem Fenster der Größe 2×2 annimmt. Die erste vollständig verbundene Schicht hat 4096 Neuronen, die zweite vollständig verbundene Schicht hat 4096 Neuronen und die letzte Schicht ist eine vollständig verbundene Schicht mit 1000 Neuronen, eines für jede Klasse des ImageNet-Datensatzes.
AlexNet führte mehrere wichtige Innovationen ein, die ihm damals eine hochmoderne Leistung ermöglichten, wie z. B. die Verwendung der ReLU-Aktivierungsfunktion , Datenerweiterung und Dropout-Regularisierung. Es hatte auch eine viel größere Kapazität als LeNet und konnte komplexere Merkmale aus den Bildern lernen.
AlexNet wurde damals allgemein als Durchbruch auf dem Gebiet der Computervision angesehen und hat viele der nachfolgenden Architekturen inspiriert.
VGGNet
VGGNet ist eine Convolutional-Neural-Network-Architektur, die von der Visual Geometry Group (VGG) an der Universität Oxford entwickelt wurde. Sie wurde 2014 in einem Artikel von Karen Simonyan und Andrew Zisserman vorgestellt und gewann damit den ILSVRC-2014-Wettbewerb.
VGGNet ist für seine Einfachheit bekannt und erreicht gleichzeitig eine gute Leistung bei Bildklassifizierungsaufgaben. Es besteht aus einem Stapel von Faltungs- und Max-Pooling-Schichten, gefolgt von vollständig verbundenen Schichten. Das Hauptmerkmal von VGGNet ist die Verwendung sehr kleiner Faltungsfilter (3×3) mit einer sehr tiefen Architektur (bis zu 19 Schichten). Diese Architektur wurde später modifiziert und als Rückgrat für verschiedene Computer Vision-Aufgaben wie Objekterkennung und Bildsegmentierung verwendet.
ResNet
Eine der größten Herausforderungen beim Training sehr tiefer neuronaler Netzwerke ist das Problem verschwindender Gradienten. Dabei werden die Gradienten (die zum Aktualisieren der Parameter während des Trainings verwendet werden) sehr klein und das Training wird langsam. ResNet (Residual Neural Network), 2015 von Microsoft Research entwickelt, behebt dieses Problem durch die Einführung des Konzepts der „Restverbindungen“.
Eine Restverbindung ist eine Abkürzungsverbindung, die eine oder mehrere Schichten umgeht und den Gradienten direkt zu früheren Schichten fließen lässt. Dadurch kann ResNet viel tiefere Netzwerke trainieren als frühere Architekturen, ohne unter dem Problem des verschwindenden Gradienten zu leiden.
ResNet-Architekturen zeichnen sich durch ihre Tiefe aus. Das ursprüngliche ResNet hatte 152 Schichten. Neuere Versionen wie ResNet-50, ResNet-101 und ResNet-152 haben jeweils 50, 101 und 152 Schichten. ResNet hat sich zu einer beliebten Wahl als Rückgrat für verschiedene Computer Vision-Aufgaben wie Objekterkennung, semantische Segmentierung und Bildklassifizierung entwickelt.
MobileNet
MobileNet wurde 2017 von Google entwickelt und ist speziell für den Einsatz auf mobilen und eingebetteten Geräten mit begrenzten Rechenressourcen konzipiert. MobileNet verwendet tiefenweise trennbare Faltungen, um die Anzahl der Parameter und den Rechenaufwand bei gleichzeitig guter Genauigkeit zu reduzieren.
Eine tiefenweise trennbare Faltung wendet auf jeden Eingangskanal einen einzelnen Faltungsfilter an (tiefenweise Faltung) und kombiniert dann die Ergebnisse mit einer punktweisen Faltung (1×1-Faltung). Dieser Ansatz reduziert die Anzahl der erforderlichen Parameter und Berechnungen im Vergleich zu Standard-Faltungsschichten.
Die MobileNet-Architektur ist auf leichtes Gewicht und Effizienz ausgelegt und eignet sich daher gut für den Einsatz auf mobilen und eingebetteten Geräten mit begrenztem Speicher und begrenzter Verarbeitungsleistung.
Das Modell ist in mehreren Versionen mit unterschiedlichen Komplexitäts- und Genauigkeitsgraden verfügbar. MobileNet V1, V2 und V3 sind die gängigsten Versionen. Die neueste Version, MobileNet V3, gilt als die effizienteste und bietet ein ausgewogenes Verhältnis zwischen Genauigkeit und Effizienz.
MobileNet wird in zahlreichen Anwendungen eingesetzt, beispielsweise zur Objekterkennung, semantischen Segmentierung und Bildklassifizierung, und dient als Rückgrat für zahlreiche Computer Vision-Aufgaben, beispielsweise zur Gesichtserkennung, Objektverfolgung und vielen mehr.
Abschluss
Convolutional Neural Networks sind eine Art Deep-Learning-Architektur, die häufig bei Computer Vision-Aufgaben wie Bildklassifizierung, Objekterkennung und semantischer Segmentierung eingesetzt wird. CNNs haben gegenüber herkömmlichen Computer Vision-Methoden mehrere Vorteile, darunter:
- Robustheit gegenüber Verschiebung und Drehung : CNNs können Merkmale erlernen, die gegenüber kleinen Änderungen der Position und Ausrichtung der Objekte im Bild robust sind, wodurch sie sich gut für Aufgaben wie Objekterkennung und semantische Segmentierung eignen.
- Umgang mit großen Datenmengen: CNNs können aus großen Datenmengen lernen, weshalb sie sich gut für das Training mit großen Datensätzen wie ImageNet eignen.
- Transferlernen: CNNs, die auf großen Datensätzen wie ImageNet trainiert wurden, können auf kleineren Datensätzen feinabgestimmt werden, was die Datenmenge und die Rechenressourcen, die zum Trainieren eines Modells für eine bestimmte Aufgabe erforderlich sind, erheblich reduzieren kann.
Andererseits sind mit CNNs auch einige Einschränkungen und Herausforderungen verbunden, darunter:
- Rechenaufwand: Für das Training und die Bereitstellung von CNNs sind erhebliche Rechenressourcen erforderlich, was bei der Bereitstellung auf mobilen und eingebetteten Geräten ein einschränkender Faktor sein kann.
- Überanpassung: CNNs können bei begrenzter Datenmenge zu Überanpassung neigen, was bei nicht angezeigten Daten zu einer schlechten Leistung führen kann.
- Erklärbarkeit: CNNs werden oft als Black Boxes betrachtet, was es schwierig macht, ihre Entscheidungsfindung zu verstehen und mögliche Fehler zu erkennen.
Zitieren Sie diesen Beitrag
Verwenden Sie den folgenden Eintrag, um diesen Beitrag bei Ihrer Recherche zu zitieren:
Petru Potrimba . (10. Februar 2023). Was ist ein Convolutional Neural Network? Roboflow-Blog: https://blog.roboflow.com/what-is-a-convolutional-neural-network/
Besprechen Sie diesen Beitrag
Wenn Sie Fragen zu diesem Blogbeitrag haben, starten Sie eine Diskussion im Roboflow-Forum .


