

Eine confusion matrix ist eine zwei mal zwei Matrix, die die Anzahl der richtigen und falschen Vorhersagen innerhalb jeder Kategorie darstellt, die sich aus Ihrem Klassifizierungsalgorithmus ergeben. In diesem Artikel werden wir die Grundlagen der Klassifizierung im maschinellen Lernen untersuchen, wie man eine confusion matrix interpretiert, welche Vorteile und Einschränkungen es gibt und für welche Art von Beruf dieses Tool von Nutzen sein könnte.
Was ist Klassifizierung beim maschinellen Lernen?
Klassifizierung im maschinellen Lernen ist wie das Sortieren von Dingen in verschiedene Gruppen basierend auf ihren Merkmalen. Stellen Sie sich beispielsweise vor, Sie haben eine Auswahl von Fotos, auf denen entweder Katzen oder Hunde zu sehen sind. Klassifizierungsalgorithmen helfen der Maschine, die Unterschiede zwischen Katzen- und Hundebildern basierend auf Merkmalen wie Farbe, Größe oder Form zu lernen. Im maschinellen Lernen können Sie dieses Konzept für komplexere Aufgaben verwenden, wie das Erkennen von Spam-E-Mails, das Diagnostizieren von Krankheiten anhand medizinischer Bilder oder das Kategorisieren von Produkten.
Klassifizierungsalgorithmen berücksichtigen mehrere unabhängige Variablen, bevor sie die Wahrscheinlichkeit berechnen, dass etwas in jede mögliche Kategorie fällt. Angenommen, Sie versuchen, einem Patienten eine medizinische Diagnose zu stellen. In diesem Fall könnten die Merkmale und Symptome des Patienten die unabhängigen Variablen sein. Wenn der Patient über 60 Jahre alt ist und unter Gelenkschmerzen und -steifheit leidet, könnte Ihr Klassifizierungsalgorithmus eine hohe prozentuale Wahrscheinlichkeit angeben, dass der Patient Arthritis hat.
Abhängig von Ihrem Algorithmus und den möglichen Kategorien finden Sie möglicherweise Wahrscheinlichkeiten, die mit anderen Erkrankungen in Zusammenhang stehen, beispielsweise Gelenkbrüchen, Krebs oder Infektionen.
Erkennen von Klassifizierungsfehlern
Nachdem Sie Ihren Klassifizierungsalgorithmus entwickelt haben, möchten Sie feststellen, wie genau Ihr Modell ist. Wenn der Algorithmus Fehler macht und Dinge falsch kennzeichnet, werden diese als falsch positiv und falsch negativ bezeichnet. Wenn beispielsweise eine sichere E-Mail als Spam markiert wird, ist dies ein falsch positives Ergebnis. Ein falsch negatives Ergebnis hingegen liegt vor, wenn der Algorithmus nicht erkennt, was er finden soll, z. B. wenn er eine Spam-E-Mail übersieht und sie in den Posteingang gelangen lässt. Idealerweise sollte Ihr Klassifizierungsalgorithmus viel höhere Raten an richtig positiven und richtig negativen als an falsch positiven und negativen Ergebnissen aufweisen.
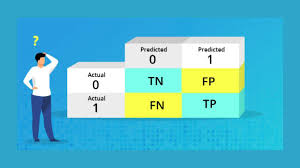
Was ist eine confusion matrix?
Eine confusion matrix ist eine praktische Möglichkeit, Ihre wahren Positiv-, wahren Negativ-, falschen Positiv- und falschen Negativwerte darzustellen. Konfusionsmatrizen werden normalerweise als 2×2-Tabelle dargestellt:
| Vorhergesagtes Negativ | Vorausgesagtes positives | |
| Tatsächlich negativ | A | B |
| Tatsächlich positiv | C | D |
In dieser confusion matrix gibt es vier Zellen:
- „D“ oder True Positives (TP): In diesen Fällen sagt das Modell die positive Klasse korrekt voraus.
- „A“ oder Echte Negative (TN): In diesen Fällen sagt das Modell die negative Klasse korrekt voraus.
- „B“ oder Falsch-Positive (FP): In diesen Fällen zeigte das Modell „positiv“ an, der wahre Wert war jedoch „negativ“. In der Statistik könnte man dies als Fehler erster Art bezeichnen.
- „C“ oder Falsch-Negative (FN): Dies sind die Fälle, in denen das Modell „negativ“ anzeigt, der wahre Wert jedoch „positiv“ ist. In der Statistik könnte man dies als Fehler 2. Art bezeichnen.
Arten von Leistungskennzahlen
Aus den vier Grundelementen einer confusion matrix (wahre Positive, wahre Negative, falsche Positive, falsche Negative) können Sie mehrere wichtige Leistungskennzahlen berechnen:
Genauigkeit:
Die Genauigkeit ist die allgemeine Richtigkeit des Modells, berechnet als (TP + TN) / (TP + TN + FP + FN).
Präzision:
Präzision ist die Genauigkeit positiver Vorhersagen, berechnet als TP / (TP + FP). Wenn Ihre Präzision 0,4 beträgt, dann ist das Modell in 40 Prozent der Fälle mit seinen positiven Vorhersagen richtig.
Sensibilität oder Erinnerung:
Die Sensitivität stellt die Fähigkeit des Modells dar, alle positiven Fälle zu finden. Wenn dieser Wert hoch ist, ist es wahrscheinlicher, dass das Modell positive Fälle erkennt. Es ist auch wahrscheinlicher, dass es falsche positive Ergebnisse gibt. Sie können dies als TP / (TP + FN) berechnen.
Besonderheit:
Die Spezifität stellt die Fähigkeit des Modells dar, negative Instanzen richtig zu klassifizieren. Dies ist das Gegenteil der Spezifität – ein höherer Wert dieser Kennzahl bedeutet, dass das Modell negative Fälle eher richtig klassifiziert. Allerdings ist es auch wahrscheinlicher, dass das Modell falsche Negative liefert, wenn diese Kennzahl hoch ist. Sie können dies als TN / (TN + FP) berechnen.
F1-Punktzahl:
Der F1-Score oder F-Maß ist ein Wert, der die Leistung eines Klassifizierungsalgorithmus darstellt. Er wird wie folgt berechnet: 2 * (Präzision * Rückruf) / (Präzision + Rückruf).
Zum Interpretieren einer confusion matrix gehört mehr als nur das Betrachten der Zahlen. Es geht darum, den Kontext des Problems zu verstehen, das Sie lösen. Wenn Sie einen Screening-Algorithmus für eine medizinische Diagnose entwickeln, möchten Sie möglicherweise falsch-negative Ergebnisse vermeiden. Stellen Sie sich beispielsweise vor, Sie sagen keine Krankheit voraus, obwohl jemand tatsächlich eine hat. In diesem Zusammenhang hätte die Vermeidung falsch-negativer Ergebnisse höchste Priorität.
Im Gegensatz dazu kann bei der E-Mail-Spamerkennung ein falscher Positivwert (Markierung einer guten E-Mail als Spam) problematischer sein. Durch die Untersuchung der Matrix können Sie feststellen, ob Ihr Modell sensibler (Erhöhung der wahren Positivwerte) oder spezifischer (Verringerung der falschen Positivwerte) sein muss, und Ihren Ansatz entsprechend anpassen.
Vor- und Nachteile der Verwendung einer confusion matrix
Wenn Sie sich für die Verwendung einer confusion matrix entscheiden, sollten Sie überlegen, ob sie für Ihren Datentyp geeignet ist und welche Leistungskennzahlen für Sie wichtig sind. Zu den wichtigsten Vorteilen und Einschränkungen, die Sie möglicherweise feststellen, zählen die folgenden.
Vorteile
Durch die Verwendung einer confusion matrix mit binären Daten können Sie mehrere verschiedene Leistungsmaße bestimmen. Mit der binären Klassifizierung können Sie die Genauigkeit, Präzision, den Rückruf, den Mathrews-Korrelationskoeffizienten, den ROC und den Bereich unter der Kurve des Modells bestimmen. Jedes dieser Maße stellt einen anderen Aspekt der Leistung Ihres Modells dar, und Sie können diese Maße verwenden, um zu bestimmen, wie Ihr Modell geändert werden muss. Wenn Sie für einen bestimmten Datentyp entwerfen, stellen Sie möglicherweise fest, dass es wichtig ist, die Kontrolle darüber zu haben, was Ihr Modell priorisiert.
Nachteile
Wenn Sie eine confusion matrix verwenden, sollten Sie den verwendeten Datentyp berücksichtigen. Konfusionsmatrizen können bei einer Mehrklassenklassifizierung komplex werden, da Sie mehr als zwei Klassen vorhersagen müssen. Mit zunehmender Zahl wird die Interpretation der Genauigkeit und Leistung Ihrer confusion matrix zunehmend komplexer. Die Mehrklassenklassifizierung ist im Vergleich zur binären Klassifizierung auch auf nur wenige Leistungsmaße beschränkt.
Verwirrungsmatrizen können auch irreführend wirken, wenn Klassenungleichgewichte vorliegen. Angenommen, Sie haben einen Datensatz mit 1.000 Werten und nur drei positiven Werten. In diesem Fall könnte Ihr Klassifizierungssystem eine hohe Genauigkeit aufweisen, indem es einfach alles als negativ vorhersagt, während es in Wirklichkeit positive Werte nicht richtig erkennen kann.
Muss lesen: Paula Dietz: Die betrogene Ehefrau des BTK-Killers
Berufe, die Konfusionsmatrizen verwenden
In vielen verschiedenen Berufen, die Sie erkunden möchten, werden Konfusionsmatrizen für Klassifizierungsaufgaben verwendet. Sie können Klassifizierungsaufgaben in Ihrer primären beruflichen Rolle verwenden, z. B. beim Entwerfen von Betrugserkennungssoftware, oder Sie können Klassifizierung als Werkzeug verwenden, um Ihre Leistung zu verbessern, z. B. bei der Verwendung eines E-Mail-Spamfilters.
Als Datenwissenschaftler können Sie eine confusion matrix verwenden, um die Genauigkeit und Präzision Ihrer Modelle zu verstehen. Diese Art der Datenwissenschaft ist auf viele Bereiche anwendbar, auf die Sie sich spezialisieren können. Als Umweltdatenwissenschaftler können Sie beispielsweise eine confusion matrix verwenden, um zu untersuchen, wie genau Ihr Klassifizierungsmodell eine genetische Variante in Ihrer Probe erkannt hat. Als Datenwissenschaftler können Sie ab Januar 2024 mit einem Jahresgehalt zwischen 112.000 und 194.000 US-Dollar rechnen, einschließlich Grundgehalt und Zusatzleistungen [ 1 ].
Lernen Sie weiter auf Coursera.
Sie können Ihr Wissen über maschinelles Lernen und Klassifizierung mit spannenden Kursen auf Coursera, die von Spitzenuniversitäten und führenden Organisationen angeboten werden, weiter vertiefen. Die Spezialisierung auf maschinelles Lernen der Stanford University ist eine großartige Möglichkeit, Ihr Wissen über zwei oder mehr Monate hinweg flexibel zu erweitern. Diese Spezialisierung auf Anfängerniveau führt Sie durch Konzepte wie das Erstellen von Modellen für maschinelles Lernen, das Trainieren neuronaler Netzwerke und das Erstellen von Empfehlungssystemen.


