

Alles, was Sie über das Random Forest Modell im maschinellen Lernen wissen müssen.
Random Forest ist ein flexibler, einfach zu verwendender Algorithmus für maschinelles Lernen , der auch ohne Hyperparameter-Optimierung in den meisten Fällen hervorragende Ergebnisse liefert. Aufgrund seiner Einfachheit und Vielseitigkeit (er kann sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden ) ist er auch einer der am häufigsten verwendeten Algorithmen .
In diesem Beitrag erläutern wir, wie der Random-Forest-Algorithmus funktioniert, wie er sich von anderen Algorithmen unterscheidet und wie man ihn verwendet.
Was ist Random Forest?
Random Forest ist ein überwachter Lernalgorithmus . Der „Wald“, den er erstellt, ist ein Ensemble von Entscheidungsbäumen , die normalerweise mit der Bagging-Methode trainiert werden. Die Grundidee der Bagging-Methode besteht darin, dass eine Kombination von Lernmodellen das Gesamtergebnis verbessert.
Einfach ausgedrückt: Random Forest erstellt mehrere Entscheidungsbäume und führt sie zusammen, um eine genauere und stabilere Vorhersage zu erhalten.
So funktioniert Random Forest
Ein großer Vorteil von Random Forest besteht darin, dass es sowohl für Klassifizierungs- als auch für Regressionsprobleme verwendet werden kann, die den Großteil der aktuellen Systeme für maschinelles Lernen ausmachen.
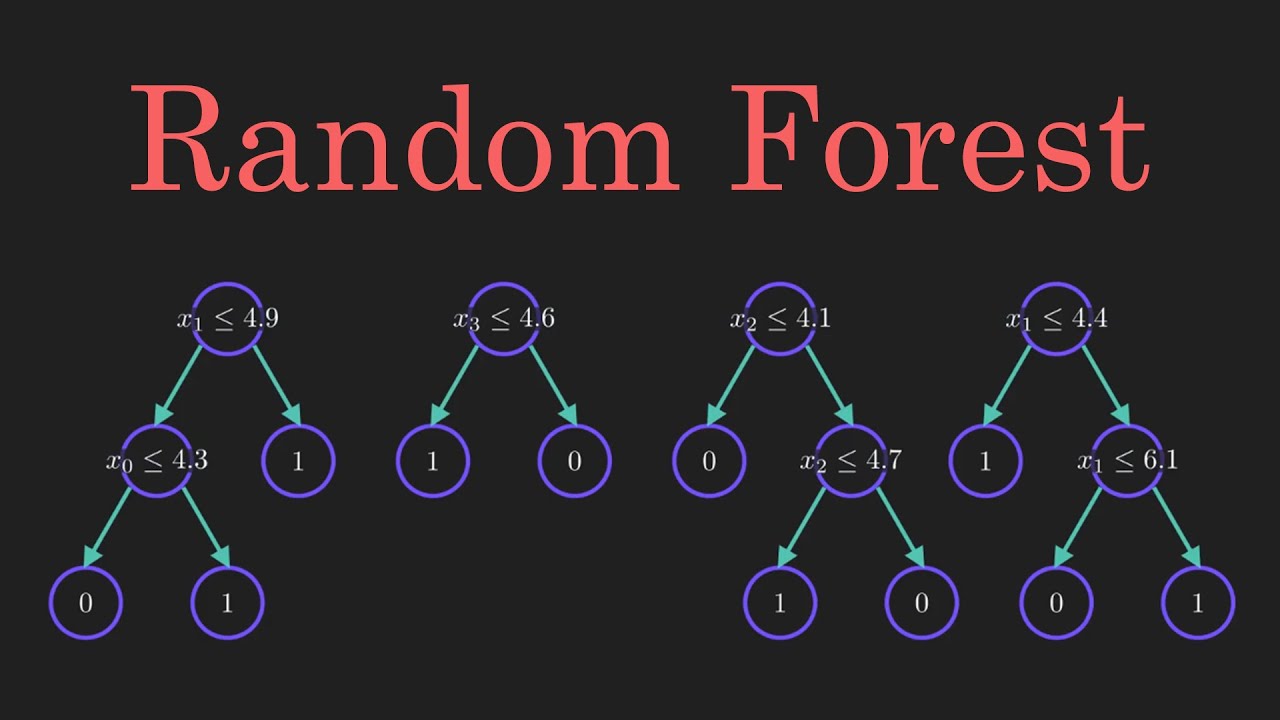
Schauen wir uns den Random Forest bei der Klassifizierung an, da die Klassifizierung manchmal als Baustein des maschinellen Lernens betrachtet wird. Unten sehen Sie, wie ein Random-Forest-Modell mit zwei Bäumen aussehen würde:
Random Forest in Klassifizierung und Regression
Random Forest hat nahezu dieselben Hyperparameter wie ein Entscheidungsbaum oder ein Bagging-Klassifikator. Glücklicherweise besteht keine Notwendigkeit, einen Entscheidungsbaum mit einem Bagging-Klassifikator zu kombinieren, da Sie problemlos die Klassifikatorklasse von Random Forest verwenden können. Mit Random Forest können Sie auch Regressionsaufgaben bewältigen, indem Sie den Regressor des Algorithmus verwenden.
Random Forest fügt dem Modell zusätzliche Zufälligkeit hinzu, während die Bäume wachsen. Anstatt beim Aufteilen eines Knotens nach dem wichtigsten Merkmal zu suchen, wird in einer zufälligen Teilmenge von Merkmalen nach dem besten Merkmal gesucht. Dies führt zu einer großen Vielfalt, die im Allgemeinen zu einem besseren Modell führt.
Daher wird in einem Random-Forest-Klassifikator nur eine zufällige Teilmenge der Merkmale vom Algorithmus zum Aufteilen eines Knotens berücksichtigt. Sie können Bäume sogar noch zufälliger machen, indem Sie zusätzlich zufällige Schwellenwerte für jedes Merkmal verwenden, anstatt nach den bestmöglichen Schwellenwerten zu suchen (wie dies bei einem normalen Entscheidungsbaum der Fall ist).
Random-Forest-Modelle vs. Entscheidungsbäume
Obwohl es sich bei einem Random-Forest-Modell um eine Sammlung von Entscheidungsbäumen handelt, gibt es einige Unterschiede .
Wenn Sie einen Trainingsdatensatz mit Merkmalen und Beschriftungen in einen Entscheidungsbaum eingeben, werden einige Regeln formuliert, die zum Treffen der Vorhersagen verwendet werden.
Um beispielsweise vorherzusagen, ob eine Person auf eine Online-Werbung klickt, könnten Sie die Anzeigen sammeln, auf die die Person in der Vergangenheit geklickt hat, sowie einige Merkmale, die ihre Entscheidung beschreiben. Wenn Sie die Merkmale und Beschriftungen in einen Entscheidungsbaum einfügen, werden einige Regeln generiert, die dabei helfen, vorherzusagen, ob die Werbung angeklickt wird oder nicht. Im Vergleich dazu wählt der Random-Forest-Algorithmus Beobachtungen und Merkmale nach dem Zufallsprinzip aus, um mehrere Entscheidungsbäume zu erstellen, und errechnet dann den Durchschnitt der Ergebnisse.
Ein weiterer Unterschied besteht darin, dass „tiefe“ Entscheidungsbäume unter Überanpassung leiden können . In den meisten Fällen verhindert der Random Forest dies, indem er zufällige Teilmengen der Merkmale erstellt und mit diesen Teilmengen kleinere Bäume baut. Anschließend kombiniert er die Teilbäume. Es ist wichtig zu beachten, dass dies nicht immer funktioniert und die Berechnung auch langsamer macht, je nachdem, wie viele Bäume der Random Forest erstellt.
Ein reales Beispiel für Random Forest
Andrew möchte entscheiden, wohin er während seines einjährigen Urlaubs reisen möchte. Deshalb bittet er die Leute, die ihn am besten kennen, um Vorschläge. Der erste Freund, den er aufsucht, fragt ihn nach den Vorlieben und Abneigungen seiner vergangenen Reisen. Basierend auf den Antworten wird er Andrew einige Ratschläge geben.
Dies ist ein typischer Ansatz für einen Entscheidungsbaumalgorithmus . Andrews Freund hat anhand von Andrews Antworten Regeln erstellt, die ihm bei der Entscheidung helfen sollen, was er empfehlen soll.
Anschließend bittet Andrew immer mehr seiner Freunde um Rat, und diese stellen ihm wiederum verschiedene Fragen, aus denen sie Empfehlungen ableiten können. Schließlich wählt Andrew die Orte aus, die ihm seine Freunde am meisten empfehlen, was dem typischen Ansatz eines Random-Forest-Algorithmus entspricht.
Bedeutung der Random-Forest-Funktion
Eine weitere großartige Eigenschaft des Random-Forest-Algorithmus ist, dass es sehr einfach ist, die relative Wichtigkeit jedes Merkmals für die Vorhersage zu messen. Sklearn bietet hierfür ein großartiges Tool, das die Wichtigkeit eines Merkmals misst, indem es untersucht, um wie viel die Baumknoten, die dieses Merkmal verwenden, die Unreinheit über alle Bäume im Wald hinweg reduzieren. Es berechnet diesen Wert nach dem Training automatisch für jedes Merkmal und skaliert die Ergebnisse so, dass die Summe aller Wichtigkeiten eins ergibt.
Wenn Sie nicht wissen, wie ein Entscheidungsbaum funktioniert oder was ein Blatt oder Knoten ist, finden Sie hier eine gute Beschreibung aus Wikipedia: „In einem Entscheidungsbaum stellt jeder interne Knoten einen ‚Test‘ für ein Attribut dar (z. B. ob beim Münzwurf Kopf oder Zahl herauskommt), jeder Zweig stellt das Ergebnis des Tests dar und jeder Blattknoten stellt eine Klassenbezeichnung dar (Entscheidung, die nach der Berechnung aller Attribute getroffen wird). Ein Knoten ohne untergeordnete Knoten ist ein Blatt.“
Indem Sie sich die Merkmalswichtigkeit ansehen, können Sie entscheiden, welche Merkmale möglicherweise weggelassen werden, da sie nicht genug (oder manchmal überhaupt nichts) zum Vorhersageprozess beitragen. Dies ist wichtig, da eine allgemeine Regel beim maschinellen Lernen lautet: Je mehr Merkmale Sie haben, desto wahrscheinlicher ist es, dass Ihr Modell unter Überanpassung leidet und umgekehrt.
Unten finden Sie eine Tabelle und eine Visualisierung, die die Bedeutung von 13 Merkmalen zeigt, die ich während eines überwachten Klassifizierungsprojekts mit dem berühmten Titanic-Datensatz auf Kaggle verwendet habe. Das gesamte Projekt finden Sie hier .
Random-Forest-Hyperparameter
Die Hyperparameter im Random Forest werden entweder verwendet, um die Vorhersagekraft des Modells zu erhöhen oder um das Modell schneller zu machen. Sehen wir uns die Hyperparameter der in sklearns integrierten Random-Forest-Funktion an.
1. Steigerung der Vorhersagekraft
Erstens gibt es den Hyperparameter n_estimators , der einfach die Anzahl der Bäume angibt, die der Algorithmus erstellt, bevor er die maximale Abstimmung vornimmt oder die Durchschnittswerte der Vorhersagen ermittelt. Im Allgemeinen erhöht eine höhere Anzahl von Bäumen die Leistung und macht die Vorhersagen stabiler, verlangsamt aber auch die Berechnung.
Ein weiterer wichtiger Hyperparameter ist max_features, also die maximale Anzahl von Features, die Random Forest zum Aufteilen eines Knotens berücksichtigt. Sklearn bietet mehrere Optionen, die alle in der Dokumentation beschrieben sind .
Der letzte wichtige Hyperparameter ist min_sample_leaf. Dieser bestimmt die Mindestanzahl an Blättern, die zum Aufteilen eines internen Knotens erforderlich sind.
2. Erhöhen der Geschwindigkeit des Random-Forest-Modells
Der Hyperparameter n_jobs teilt der Engine mit, wie viele Prozessoren sie verwenden darf. Wenn er den Wert eins hat, kann sie nur einen Prozessor verwenden. Ein Wert von „-1“ bedeutet, dass es keine Begrenzung gibt.
Der Hyperparameter random_state macht die Ausgabe des Modells replizierbar. Das Modell wird immer dieselben Ergebnisse liefern, wenn es einen bestimmten Wert von random_state hat und wenn ihm dieselben Hyperparameter und dieselben Trainingsdaten zugewiesen wurden.
Schließlich gibt es noch den oob_score (auch oob-Sampling genannt), eine Methode zur Kreuzvalidierung im Random-Forest -Stil. Bei diesem Sampling wird etwa ein Drittel der Daten nicht zum Trainieren des Modells verwendet und kann zur Bewertung seiner Leistung herangezogen werden. Diese Stichproben werden als Out-of-Bag-Stichproben bezeichnet. Sie ist der Leave-One-Out-Kreuzvalidierungsmethode sehr ähnlich, verursacht jedoch fast keinen zusätzlichen Rechenaufwand.
Vor- und Nachteile des Random-Forest-Modells
Vorteile von Random Forest
Einer der größten Vorteile von Random Forest ist seine Vielseitigkeit. Es kann sowohl für Regressions- als auch für Klassifizierungsaufgaben verwendet werden und es ist auch einfach, die relative Bedeutung anzuzeigen, die es den Eingabefunktionen zuweist.
Random Forest ist auch ein sehr praktischer Algorithmus, da die von ihm verwendeten Standard-Hyperparameter häufig zu guten Vorhersageergebnissen führen. Das Verständnis der Hyperparameter ist ziemlich einfach und es gibt auch nicht so viele davon.
Eines der größten Probleme beim maschinellen Lernen ist die Überanpassung, aber dank des Random-Forest-Klassifikators passiert dies meistens nicht. Wenn es im Wald genügend Bäume gibt, wird der Klassifikator das Modell nicht überanpassen.
Nachteile von Random Forest
Die Hauptbeschränkung von Random Forests besteht darin, dass eine große Anzahl von Bäumen den Algorithmus zu langsam und ineffektiv für Echtzeitvorhersagen machen kann. Im Allgemeinen sind diese Algorithmen schnell zu trainieren, aber nach dem Training ziemlich langsam bei der Erstellung von Vorhersagen. Eine genauere Vorhersage erfordert mehr Bäume, was zu einem langsameren Modell führt. In den meisten realen Anwendungen ist der Random-Forest-Algorithmus schnell genug, aber es kann durchaus Situationen geben, in denen die Laufzeitleistung wichtig ist und andere Ansätze vorzuziehen wären.
Und natürlich ist Random Forests ein prädiktives Modellierungstool und kein beschreibendes Tool. Das heißt, wenn Sie nach einer Beschreibung der Beziehungen in Ihren Daten suchen, wären andere Ansätze besser.
Random Forest-Anwendungen
Der Random Forest-Algorithmus wird in vielen verschiedenen Bereichen verwendet, beispielsweise im Bankwesen, an der Börse, in der Medizin und im E-Commerce .
Im Finanzwesen wird er beispielsweise eingesetzt, um Kunden zu identifizieren, die ihre Schulden eher pünktlich zurückzahlen oder die Dienste einer Bank häufiger nutzen. In diesem Bereich wird er auch eingesetzt, um Betrüger zu identifizieren, die die Bank betrügen wollen. Im Handel kann der Algorithmus verwendet werden, um das zukünftige Verhalten einer Aktie zu bestimmen datacamp.
Im Gesundheitswesen wird es verwendet, um die richtige Kombination von Komponenten in Medikamenten zu ermitteln und die Krankengeschichte eines Patienten zu analysieren, um Krankheiten zu identifizieren.
Random Forests wird im E-Commerce verwendet, um zu bestimmen, ob einem Kunden das Produkt tatsächlich gefallen wird oder nicht.
Zusammenfassung des Random Forests Classifier
Random Forests ist ein großartiger Algorithmus, um ihn früh im Modellentwicklungsprozess zu trainieren und seine Leistung zu testen. Seine Einfachheit macht den Aufbau eines „schlechten“ Random Forests zu einem schwierigen Unterfangen.
Der Algorithmus ist auch eine gute Wahl für alle, die schnell ein Modell entwickeln müssen. Darüber hinaus bietet er einen ziemlich guten Indikator für die Bedeutung, die er Ihren Merkmalen zuschreibt.
Auch in puncto Leistung sind Random Forests kaum zu schlagen. Natürlich kann man immer ein Modell finden, das eine bessere Leistung bietet – wie zum Beispiel ein neuronales Netzwerk –, aber die Entwicklung dieser Modelle nimmt normalerweise mehr Zeit in Anspruch, obwohl sie viele verschiedene Merkmalstypen verarbeiten können, wie binäre, kategorische und numerische.
Insgesamt ist Random Forests ein (meistens) schnelles, einfaches und flexibles Tool, allerdings nicht ohne Einschränkungen.
Häufig gestellte Fragen
Random Forests ist ein Algorithmus, der einen „Wald“ aus Entscheidungsbäumen generiert. Anschließend kombiniert er diese vielen Entscheidungsbäume, um Überanpassung zu vermeiden und genauere Vorhersagen zu erzielen.
Der Unterschied zwischen Entscheidungsbäumen und Random Forests besteht darin, dass Entscheidungsbäume bei der Suche nach dem besten Ergebnis auf Grundlage der bereitgestellten Daten alle möglichen Ergebnisse berücksichtigen; Random Forests generiert zufällige Vorhersagen aus mehreren Entscheidungsbäumen und mittelt diese. Infolgedessen können Entscheidungsbäume Opfer von Überanpassung werden, was bei Random Forests nicht der Fall ist.
Der Random Forests erzeugt mehrere Entscheidungsbäume, wobei beim Aufteilen der Knoten zum Erstellen der einzelnen Bäume zufällig Merkmale für die Entscheidungsfindung ausgewählt werden. Anschließend werden diese zufälligen Beobachtungen aus jedem Baum genommen und gemittelt, um ein endgültiges Modell zu erstellen.
Random Forests ist ein überwachter Algorithmus für maschinelles Lernen. Das heißt, er verwendet gekennzeichnete Trainingsdaten, um dem System zu helfen, Muster zu erkennen und Ergebnisse genau vorherzusagen.


